在 DeepSeek 掀起的这轮开源模型浪潮中,有一个开源王者似乎被遗忘了——Meta AI。 今天凌晨, Meta 突然掏出了 Llama 4。 💡 Llama 4 全系采用混合专家(MoE)架构,目前最强的开源多模态大模型 ✏️划重点:文本、图像与视频的全能选手 Llama 4 Scout 📌 面向文档摘要与大型代码库推理任务,专为高效信息提取与复杂逻辑推理打造。 🔢 共有 1090 亿参数,170 亿激活参数量 🔍 上下文长度 1000 万 tokens(目前行业最长) Llama 4 Maverick 📌 以通用助手与聊天应用为核心,具备顶级的多语言支持与编程能力。 🔢 共有 4000 亿参数,170 亿激活参数量,分布于 128个专家模块 🥇 在大模型竞技场(Arena)中突破 1400 分,总排名第二;其中开放模型超越 DeepSeek V3 排名第一。 下载 🔗 https://www.llama.com/llama-downloads/ 值得一提的是,Llama 4 Scout 使用 Int4 量化就可以在单个 H100 GPU 上运行,Llama 4 Maverick 则可以直接在 H100 主机上运行。 Llama 4 Behemoth(预览) 📌 未来最强大的 AI 模型之一,具备令人瞩目的超大规模参数架构。 🔢 2880 亿激活参数量,总参数 2 万亿(消费级根本跑不动) 🚀 目标:在多模态处理与推理能力上实现突破 ❓ 这么庞大的模型训练需要巨量计算资源和时间,据悉在推理和数学任务等技术基准上仍未达预期。 APPSO 发现,这次的发布多少有些赶鸭子上架,2 万亿参数的性能猛兽 Llama 4 Behemoth 还是期货,可见在耗费巨额资金训练后依然不够竞争力。 年初曾有消息称 DeepSeek 让 Meta AI 团队陷入恐慌: 「当生成式 AI 组织中的每个高管薪资都比训练整个 DeepSeek-V3 的成本还要高,而我们有好几十个这样的高管,他们要如何面对高层?」 开源模型已经展现出匹敌 OpenAI 等闭源模型的的能力,但 Meta 的开源王者地位开始动摇(别忘了还有 Qwen),今年的开源模型竞争逐渐白热化。 DeepSeek 前两天悄悄发布了新论文,或许 R2 已经在路上。

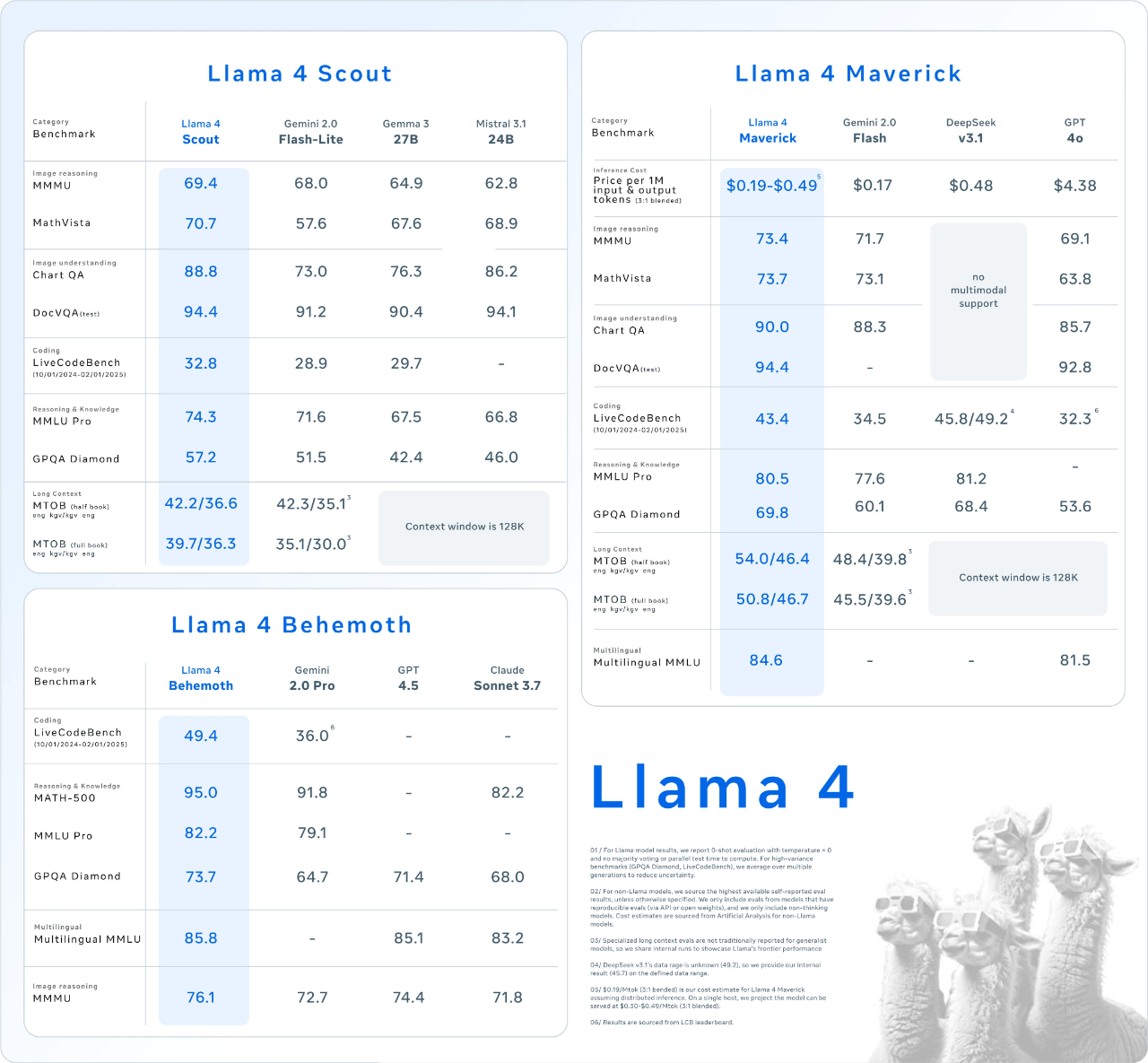
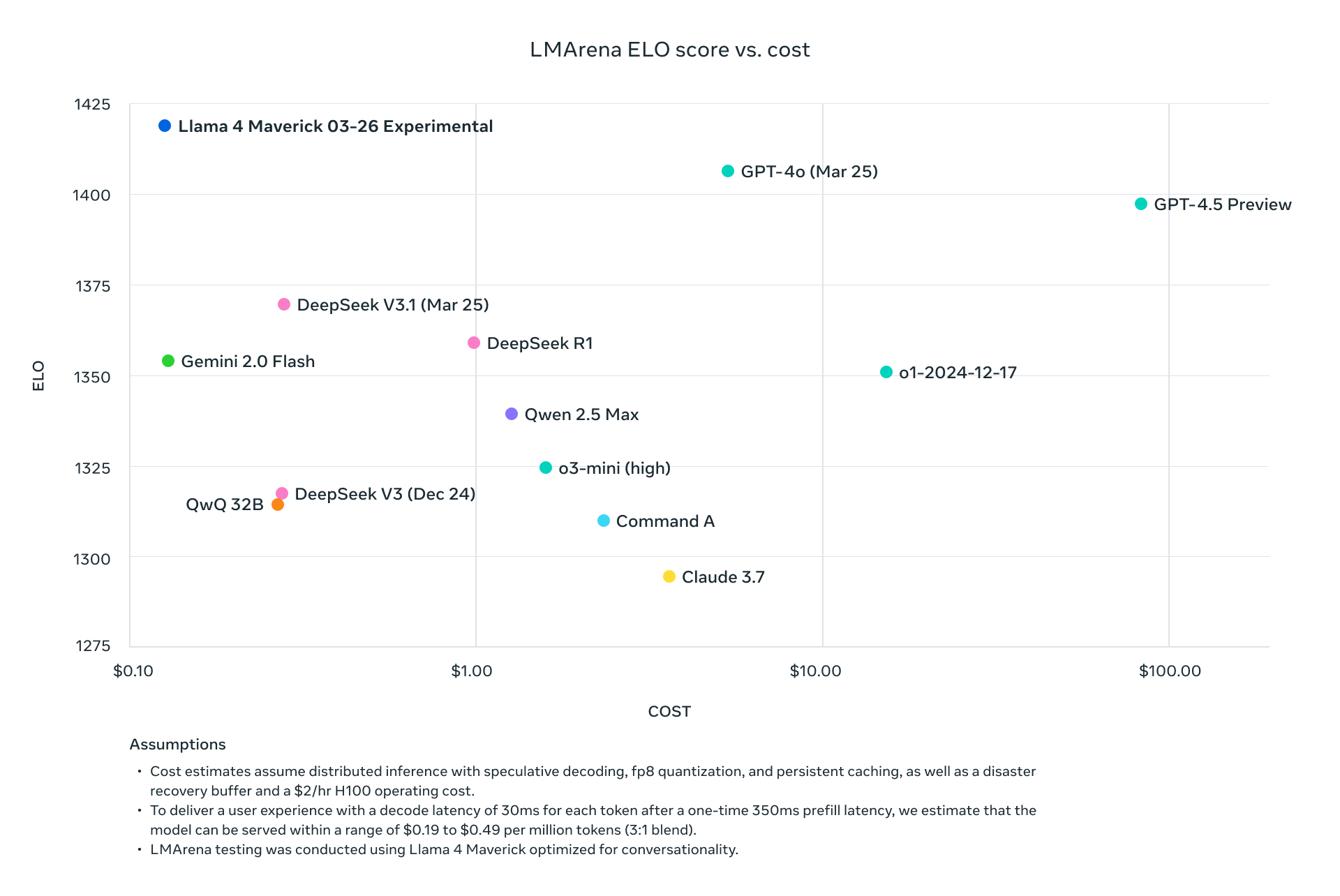
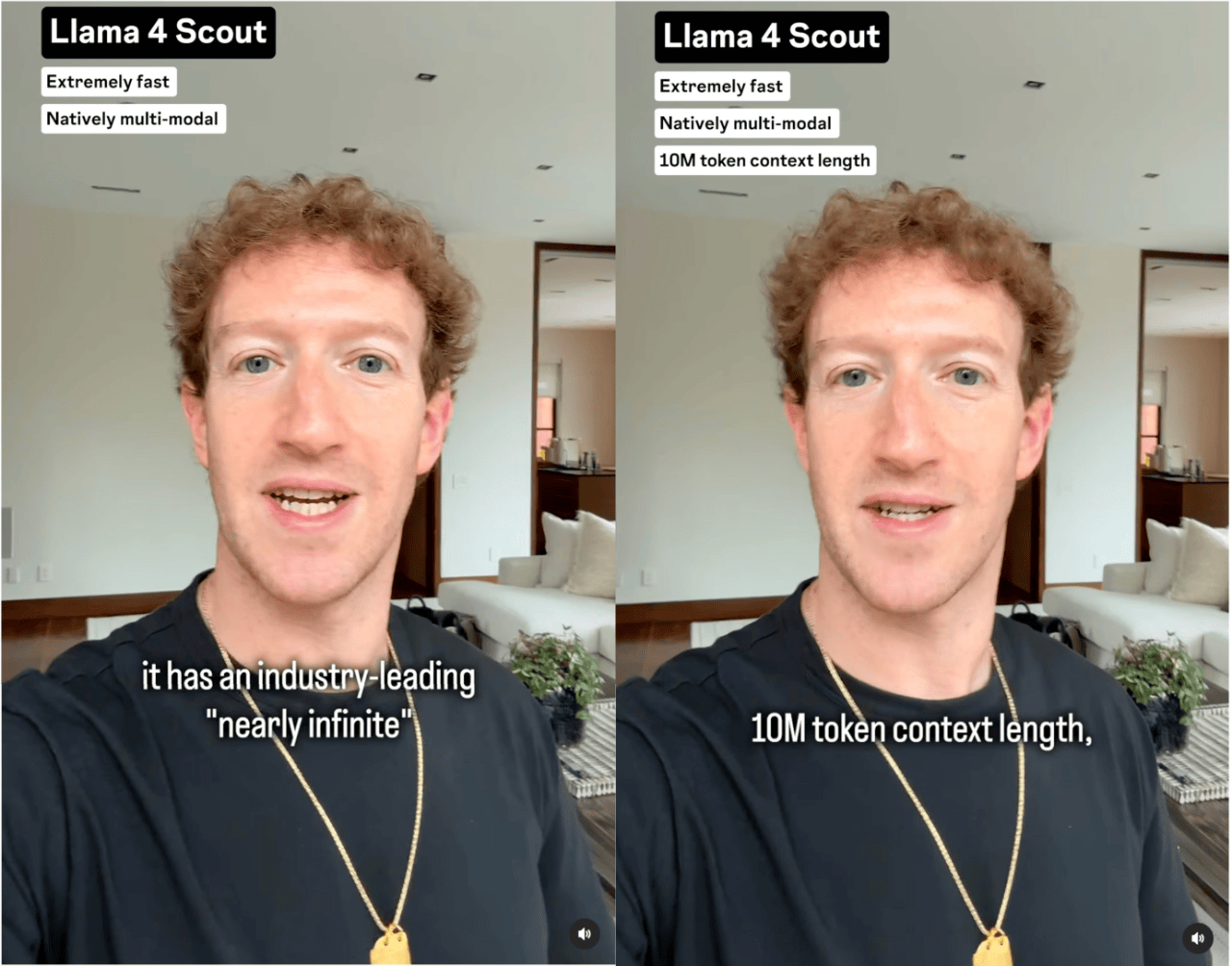
在 DeepSeek 掀起的这轮开源模型浪潮中,有一个开源王者似乎被遗忘了——Meta AI。 今天凌晨, Meta 突然掏出了 Llama 4。 💡 Llama 4 全系采用混合专家(MoE)架构,目前最强的开源多模态大模型 ✏️划重点:文本、图像与视频的全能选手 Llama 4 Scout 📌 面向文档摘要与大型代码库推理任务,专为高效信息提取与复杂逻辑推理打造。 🔢 共有 1090 亿参数,170 亿激活参数量 🔍 上下文长度 1000 万 tokens(目前行业最长) Llama 4 Maverick 📌 以通用助手与聊天应用为核心,具备顶级的多语言支持与编程能力。 🔢 共有 4000 亿参数,170 亿激活参数量,分布于 128个专家模块 🥇 在大模型竞技场(Arena)中突破 1400 分,总排名第二;其中开放模型超越 DeepSeek V3 排名第一。 下载 🔗 https://www.llama.com/llama-downloads/ 值得一提的是,Llama 4 Scout 使用 Int4 量化就可以在单个 H100 GPU 上运行,Llama 4 Maverick 则可以直接在 H100 主机上运行。 Llama 4 Behemoth(预览) 📌 未来最强大的 AI 模型之一,具备令人瞩目的超大规模参数架构。 🔢 2880 亿激活参数量,总参数 2 万亿(消费级根本跑不动) 🚀 目标:在多模态处理与推理能力上实现突破 ❓ 这么庞大的模型训练需要巨量计算资源和时间,据悉在推理和数学任务等技术基准上仍未达预期。 APPSO 发现,这次的发布多少有些赶鸭子上架,2 万亿参数的性能猛兽 Llama 4 Behemoth 还是期货,可见在耗费巨额资金训练后依然不够竞争力。 年初曾有消息称 DeepSeek 让 Meta AI 团队陷入恐慌: 「当生成式 AI 组织中的每个高管薪资都比训练整个 DeepSeek-V3 的成本还要高,而我们有好几十个这样的高管,他们要如何面对高层?」 开源模型已经展现出匹敌 OpenAI 等闭源模型的的能力,但 Meta 的开源王者地位开始动摇(别忘了还有 Qwen),今年的开源模型竞争逐渐白热化。 DeepSeek 前两天悄悄发布了新论文,或许 R2 已经在路上。
本文来自网络,不代表天羊新闻网立场,转载请注明出处:http://qces.cn/15049.html




 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






